Constructing Order Without Time
Part 3: How distributed systems track causality
If you’ve made it this far, you’ve accepted a few uncomfortable truths:
Clocks lie. Ordering isn't about time. Causality is what actually matters. And sometimes, even that isn't enough.
So, if we can’t rely on clocks, how do systems keep track of order at all?
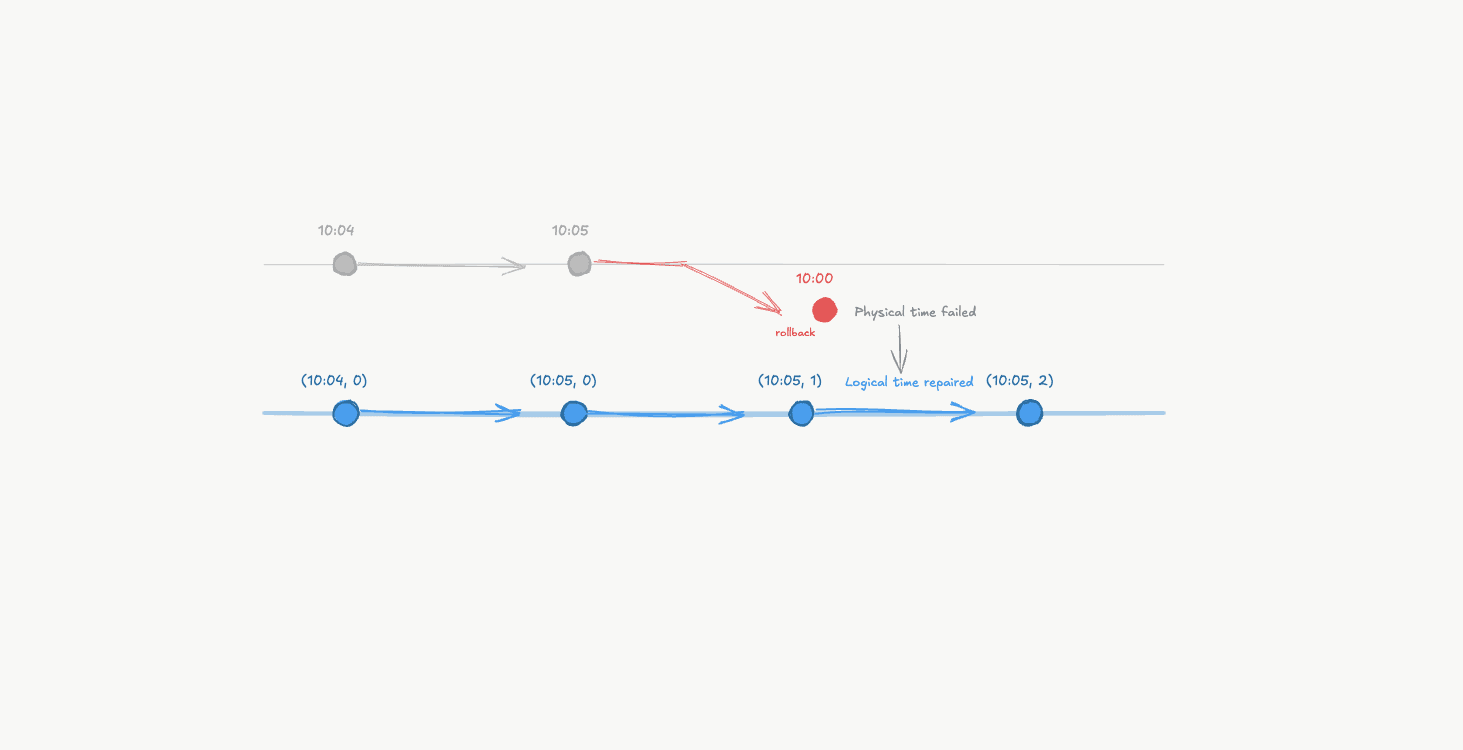
They invent their own time.
Not physical time. Logical time.
We stop looking at the sun and start counting.
Logical Clocks
A logical clock doesn’t try to tell you what time it is.
It doesn’t know about seconds. It doesn’t care about time zones. It doesn’t try to match the real world.
A logical clock answers one question: What is the order of events?
Instead of measuring time, it tracks relationships. Instead of counting seconds, it counts causality. Instead of measuring the universe, it measures influence.
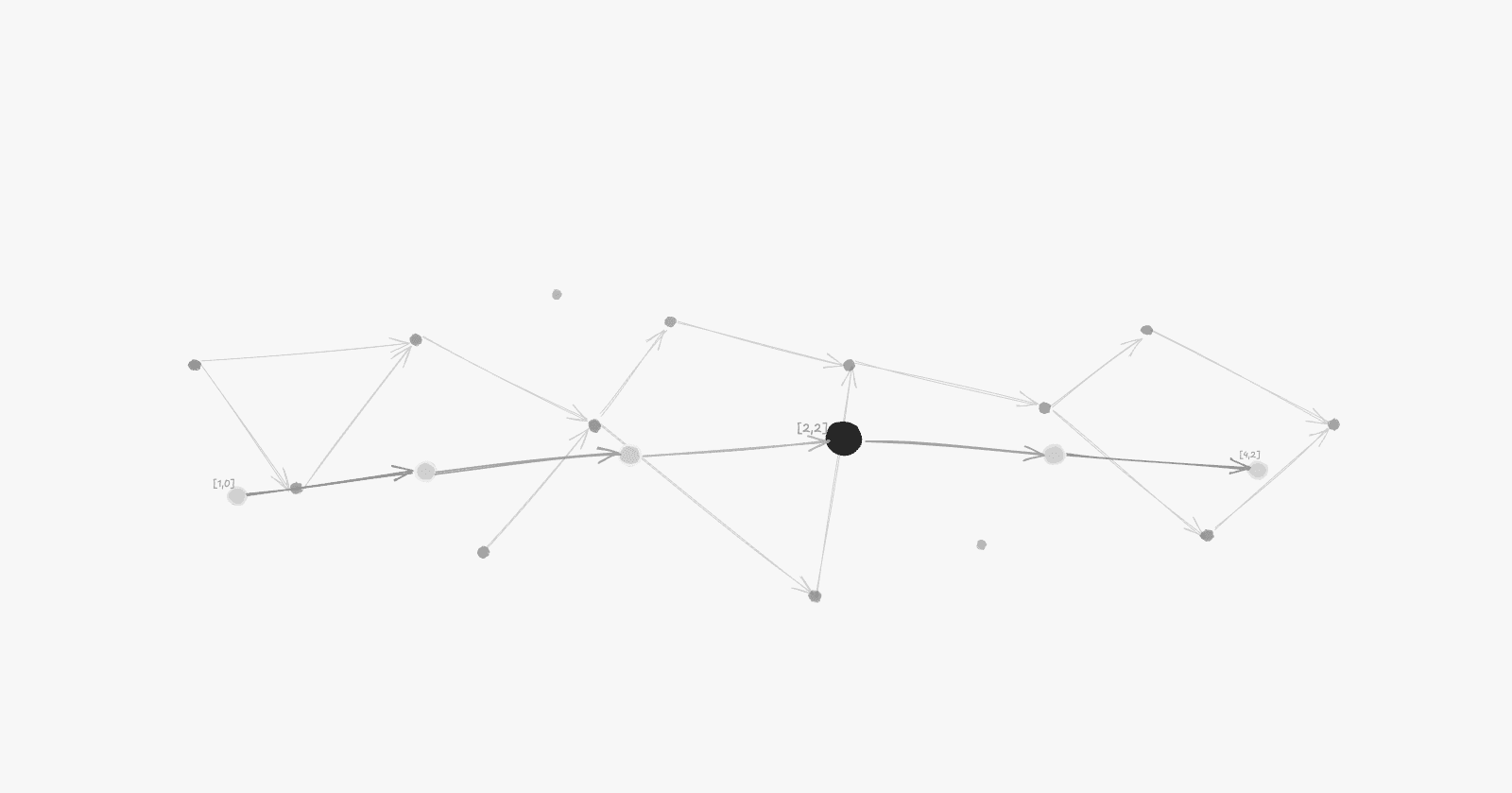
Every process keeps a counter. When something happens locally, it increases. When a message is sent, the current value goes with it. When a message is received, the counter updates to reflect what it just learned.
That’s it.
Logical clocks track how information flows through the system. They are a map of who talked to whom and in what order.
Why this works
Remember happens-before?
If A → B, we want B’s timestamp to reflect that it came after A.
Logical clocks guarantee exactly that.
No GPS. No quartz crystals. No atomic time. Just counters and message exchange.
They don't solve every problem. They won't tell you what time to meet for lunch, and they won't give you a global "now."
But they solve the right problem: detecting order when it exists.
And there isn’t just one kind.
Lamport clocks use a simple counter to preserve causal order. Vector clocks detect concurrency. Hybrid clocks blend physical and logical time.
Each exists because different systems need different trade-offs.
The simplest one, the one that started it all, is just a counter, and it is surprisingly powerful.
Lamport Clocks: The Simple Counter
Leslie Lamport's insight was that if we can't trust seconds, we can at least trust counting.
Lamport clocks are simple. Each process keeps a single integer counter. That’s it.
With that one number, we can preserve causal ordering across a distributed system.
Lamport clocks follow three simple rules.
The Local Rule: Every time a machine does something (writes to a disk, processes a request), it increments its own counter by 1.
The Sending Rule: When a machine sends a message, it attaches its current counter value to that message.
The Receiving Rule: When a machine receives a message, it takes the higher of its own counter and the received one, then adds 1. That's just:
max(local_counter, received_counter) + 1.
That’s the whole algorithm.

Lamport clock update on message receive: Process B advances its counter to preserve causality after receiving a message from Process A.
Every event gets a logical timestamp.
Lamport clocks guarantee that if A → B, then timestamp(A) < timestamp(B). If I am at "Logical Time 5" and I send you a message, whatever you do next must be at least "Logical Time 6."
Causality is preserved.
No clocks drifting. No NTP. No leap seconds. Just integers increasing in response to information flow.
And for many distributed systems, that’s enough.
The catch
Lamport clocks preserve causality. But they do not capture it completely.
If you see that timestamp(A) < timestamp(B), that does not necessarily mean: A → B.
Because Lamport clocks collapse everything into a single number, and a single number forces a comparison even when one doesn't exist.
Two concurrent events will still receive different timestamps. One smaller, one larger. But that ordering might be arbitrary.
Lamport clocks give us: If A → B, then LC(A) < LC(B)
But they do not give us: If LC(A) < LC(B), then A → B
The arrow only goes one way.
Causality implies ordering. Ordering does not imply causality.
Lamport clocks are lossy. They tell you what couldn’t have happened. But they can't prove what did.
That asymmetry matters.
Turning Lamport clocks into total order
If we take Lamport timestamps and add a tie-breaker. For example, process ID, we can force a total order.
For any two events:
Compare their timestamps.
If equal, compare process IDs.
Now every pair of events is comparable. We’ve flattened the causal web into a single sequence.
But that total order is artificial. It respects causality where it exists, but it also imposes order where none existed.
When it’s enough
Lamport clocks are simple, lightweight, cheap to maintain, and easy to implement.
They’re often enough when:
You need to preserve causality.
You want to impose a deterministic order.
You don’t need to detect concurrency explicitly.
But sometimes you don’t just want to know which event has the smaller number. You want to know whether two events were independent.
Did two users edit the same file without seeing each other’s changes? Did two replicas diverge without knowing it?
A single counter can’t answer that.
Because to detect independence, you need more than order.
You need ancestry.
Vector Clocks: Tracking the Ancestry
Lamport clocks gave us order. But they did it by collapsing everything into a single number.
That number preserved causality. But it erased independence.
If two events were concurrent, Lamport would still force one to look “earlier.”
Sometimes that’s fine. But sometimes, you don’t just want order. You want to know: “Were these two events independent?”
To answer that, you need more than a single counter.
You need memory.
Instead of one number per process, each process keeps a vector: one slot for every process in the system. If there are three processes- A, B, and C, each process maintains: [A_count, B_count, C_count]
Each position tells you how many events from that process have been seen. Not just locally. Globally, from their perspective.
The rules follow the same shape as Lamport, but trade simplicity for information.
The Local Rule: Increment only your own position in the vector. If Machine A does something, it only increments its own slot in the vector:
[A: 1, B: 0, C: 0].The Sending Rule: Attach your entire vector to the message. You're not just sending the time. You're sending your worldview.
The Receiving Rule: For every position, take the maximum of your current value and the received value. Then increment your own slot. When you receive a message, you merge histories.

Process B merges A’s history and advances, while Process C evolves independently. Revealing causality and concurrency.
We can now compare events. That gives us something Lamport couldn't.
Event A happened-before B if every element in A’s vector is ≤ B’s vector, and at least one is strictly less.
If neither vector is less than the other, they are concurrent. Not maybe. Provably independent.
Example:
A: [2,1]
B: [1,2]
Each is greater in one dimension. Neither contains the other. That is concurrency.
A vector clock is not a timestamp. It’s a summary of ancestry.
When I receive your vector, I don’t just learn when something happened.
I learn who influenced you.
If my vector is: [A:5, B:2, C:8], I am saying: I have seen 5 events from A, 2 from B, 8 from C.
It’s a compact map of causal history.
Lamport gave us a line. Vector clocks give us the tree.
The "Shopping Cart" Problem
Imagine you are shopping:
You add a book to your cart on your phone.
Your phone loses signal or goes offline.
You add a shirt on your laptop.
These two updates happened on different machines. They never saw each other.
With Lamport clocks, the system would assign different numbers and pick a “winner” using an arbitrary tie-breaker.
Oops. Your book disappears.
The system “resolved” a conflict you didn't even know you had by deleting data.
But with Vector Clocks, the database looks at the ancestry and sees the truth: these updates are concurrent.
It doesn’t guess. It keeps both. It says: “I have two independent versions of this cart. I’m going to keep both, and the next time the user is online, I’ll let them merge the two.”

Two replicas diverge without communication; on merge, their concurrent updates are preserved rather than forced into an order.
This is exactly how systems like Amazon Dynamo or Riak detect conflicts. They don't try to force a "fake" order on independent events. They detect concurrency first. Resolution comes later.
The Trade-off
Vector clocks are expressive. But they’re also expensive.
They require:
O(n) metadata per event. The size of the timestamp grows with the number of machines. If you have 1,000 nodes, every single message has to carry 1,000 integers.
Larger messages. The full vector travels with each message.
Knowledge of all participants.
Complexity of membership management when nodes join/leave.
That does not scale casually.
Vector clocks are the “don’t lose data” tool. You pay in metadata to preserve independence.
When they make sense
Vector clocks are the right tool when:
You need to detect concurrent updates.
You want to resolve conflicts intelligently.
You care about causality and independence.
They show up in systems like version control, distributed databases, and conflict-resolution protocols.
But they are heavy. And sometimes, we still want something close to real-world time.
Just not blindly.
The Takeaway
We started this journey by saying: Clocks lie.
They do. But understanding how they lie is what lets us design around them.
Physical clocks approximate reality. Logical clocks preserve causality. Vector clocks detect independence.
We can now track causality and detect independence without ever looking at a wall clock.
But in doing so, we've lost the real world.
Causality tells you what came before what. It tells you nothing about when.
So what happens when the real world matters? When “what happened before what” isn’t enough?
Can we bring the clock back, without breaking everything we just fixed?
Continue to the final part: Hybrid Logical Clocks - Having Your Cake and Eating It, Too