Ordering ≠ time
Part 2: If timestamps lie, what actually determines order?

After Part 1, if you are feeling a little betrayed, that’s reasonable. We learned that clocks drift, time can jump, machines disagree, and “now” is mostly a polite suggestion.
We took the most fundamental tool in our toolkit, the timestamp, and discovered it’s just a local guess wearing a fancy suit.
But this realisation leads us to a more interesting question: If we can't trust the clock to tell us the order of events, what can we trust?
Before we answer that, here’s the twist: Ordering was never about time in the first place.
The "WhatsApp" revelation
Think about the group chat on your phone.
If I send a message asking, "Who wants pizza?"
And you reply, "I do!"
The order matters.
If your reply arrives "before" my question, the conversation makes no sense.
But notice something important. We don’t care what time those messages were sent.
We care that:
your reply came after my question,
and that it depended on it.
When we say we want to order events, we don’t actually care about wall-clock time. We care about something much more specific: “Did one event have the chance to influence another?”
We are not asking:
“Which happened at 09:00:01?”
“Which machine had the smaller number?”
But:
Did event B know about event A?
Could B have seen A’s effects?
Was there a dependency between them?
This is a question about causality, not clocks.
A distributed example
Imagine two machines. Machine A writes a value. Machine B later reads that value.
Even if both clocks are wrong, one thing must be true: The write happened before the read, in a way that mattered.
Not before in universal time. Before in causal reality.
The read depends on the write. That dependency is the ordering.

A write on Machine A causally precedes a read on Machine B via message passing.
Now imagine something different:
Machine A updates User 1’s profile.
Machine B updates User 2’s profile at roughly the same time.
These two events may happen milliseconds apart. Or at the exact same time.
It doesn’t matter.
They are independent.
Neither could possibly have influenced the other.
Trying to force them into a single timeline doesn’t add clarity. It adds constraints.
Time answers the wrong question
Physical time tries to answer: “When did this happen relative to the universe?”. Distributed systems don’t need that. They need to answer: “Which events could have affected which other events?”
Two events can:
have perfectly ordered timestamps,
look clean and sequential,
and still be completely unrelated.
And two events can:
look simultaneous,
have misleading timestamps,
and be tightly linked by cause and effect.
Time can’t tell the difference. But the relationship between the events can.
The shift
This is the part where the ground finally stops moving. Soon, you will understand that ordering isn’t about placing everything on a single global timeline. It’s about identifying dependencies.
Some events are connected. Others are independent.
If event A caused event B, that relationship matters.
If A and B are unrelated, forcing an order between them is artificial. And, sometimes expensive.
This is why distributed systems don’t start with clocks.
They start with a rule: If A could have influenced B, then A must come before B.
That’s the entire foundation.
And this rule has a name.
Happens-Before: A language for causality
It’s not a timestamp. It’s not a clock. It’s a relationship.
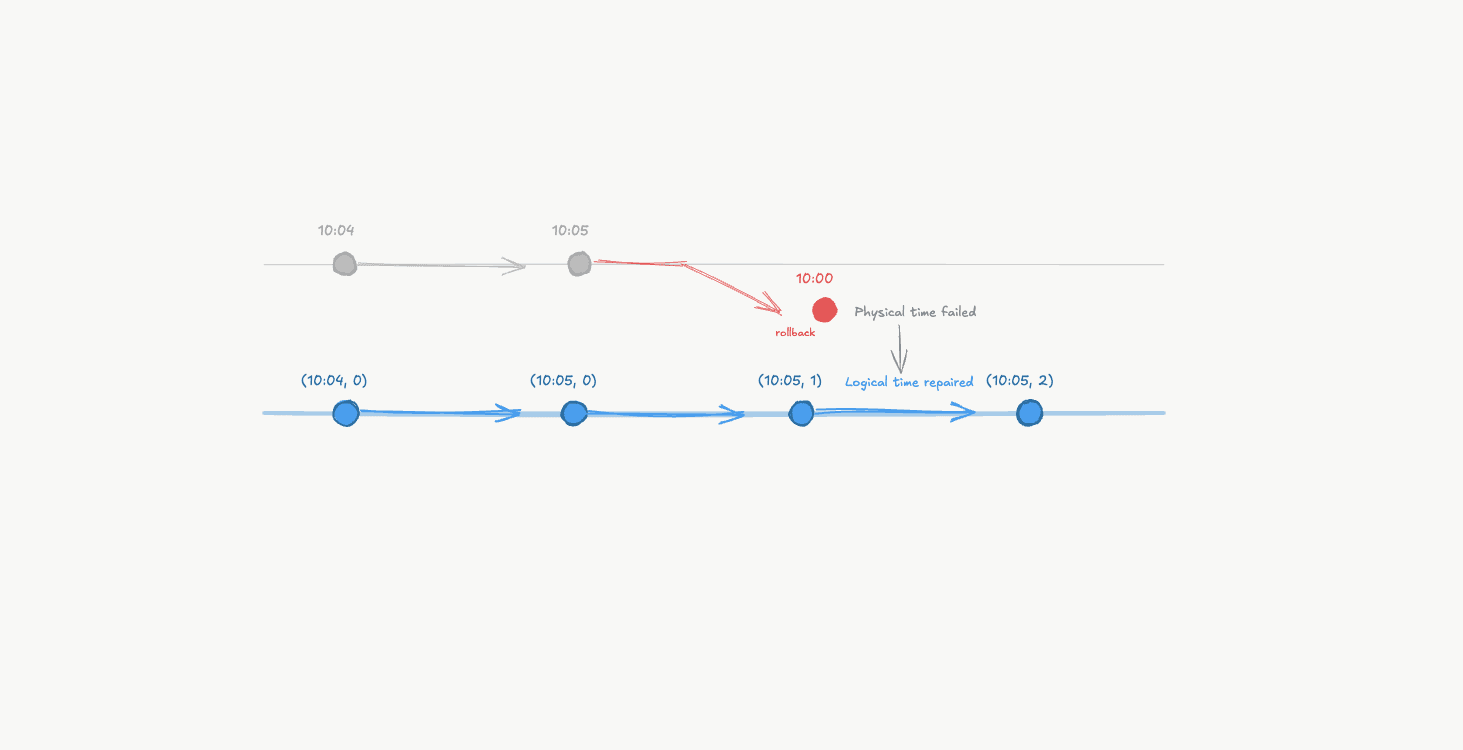
Back in 1978, Leslie Lamport made a simple observation that would fundamentally change how we reason about distributed systems.
We don’t actually need clocks to determine order.
We need to track how information flows.
He introduced a concept called happens-before. The idea is almost embarrassingly simple: If Event A could have influenced Event B, then A happened before B.
Lamport wrote it like this: A → B . Which simply means: A happens-before B.
But forget the notation for a moment. The intuition is more important. There are only three ways we can say, with certainty, that one event came before another, without looking at a clock.
Order inside a single process
If a program executes:
Step 1
Then, Step 2
Step 1 happened before Step 2.
Not because of timestamps. Because programs execute instructions in sequence.
Within a single process or thread, order is clear.
If a and b are events in the same process, and a occurs before b, then a → b
Message passing
Now, imagine I send you an email.
You read it. You reply.
Your reply could not exist without my original email.
Even if my server thinks it’s 09:00 and yours thinks it’s 08:00, the reply depends on the message.
The data flow proves the order.
Cause precedes effect.
If a is the sending of a message and b is the receipt of that same message, then a → b

A message sent from Machine A travels through the network and is received by Machine B, establishing a causal relationship where the receive depends on the send.
Transitivity
This is the subtle part that actually makes the whole system work. It’s the "friend of a friend" rule for data.
If:
A happened before B,
and B happened before C,
Then A happened before C.
Even if A and C never directly communicated.
If a → b and b → c , then a → c .
This chaining of influence is what lets distributed systems reason about entire histories without ever asking, “What time was it?” If we can trace the path of messages, we don't need to guess about the timing. The relationship is set in stone.
What happens-before does not say
Happens-before does not force every event into a single timeline.
If two events:
occur on different machines,
never exchange messages,
and never influence each other,
Then neither happened-before the other.
They are concurrent.
Our instinct is to ask: which one came first? Which one “won”? Which one happened at 09:00:00.001?
But in a distributed system, concurrency isn’t an error or a calculation we haven’t finished yet.
It’s a fact. It’s the system admitting: "These two events are strangers. Their order doesn't exist."
Causality
We can stop dancing around it. What we’ve really been talking about this whole time is called Causality.
If event A could have influenced event B, then A is a cause and B is an effect.
Happens-before is simply the formal way of capturing causal relationships. It’s a record of potential influence.
If there is no causal relationship between two events, then neither happened-before the other. The two events are independent and therefore concurrent.
And that distinction, causal vs independent, is the key to everything that comes next.
Why this changes everything
Here’s what changed. We replaced “What time is it?” with “What could this event have known?”
We traded timestamps with relationships.
And suddenly, ordering doesn’t depend on synchronised clocks, atomic hardware, or GPS satellites.
It depends on causality.
That’s the foundation.
Partial Ordering
Once you accept causality as the foundation, a trade-off appears: Not every pair of events can be compared.
In a world governed by happens-before, some events have a clear relationship:
A caused B
B depends on A
Information flowed from A to B
But other events have no relationship at all.
They happened on different machines. They never exchanged messages. They never influenced each other.
In this world, trying to say which one “came first” is meaningless.
Not everything needs to be ordered
In everyday life, we’re used to total order. We assume everything in the universe is waiting in a single line.
Monday comes before Tuesday.
Page 3 comes before Page 4.
09:00 comes before 09:01.
Everything fits neatly on a single axis.
However, distributed systems don’t work that way.
Instead of a single straight timeline, you get something more like a web. Some events are connected. Others happen independently.
Think of it like lineage. You can say your grandfather came before your father. But can you say your friend came before your cousin?
Of course not. They are independent.
If A → B, then A must come before B.
But if A and C are unrelated, there is no rule that says one must come before the other.
That’s a partial order.

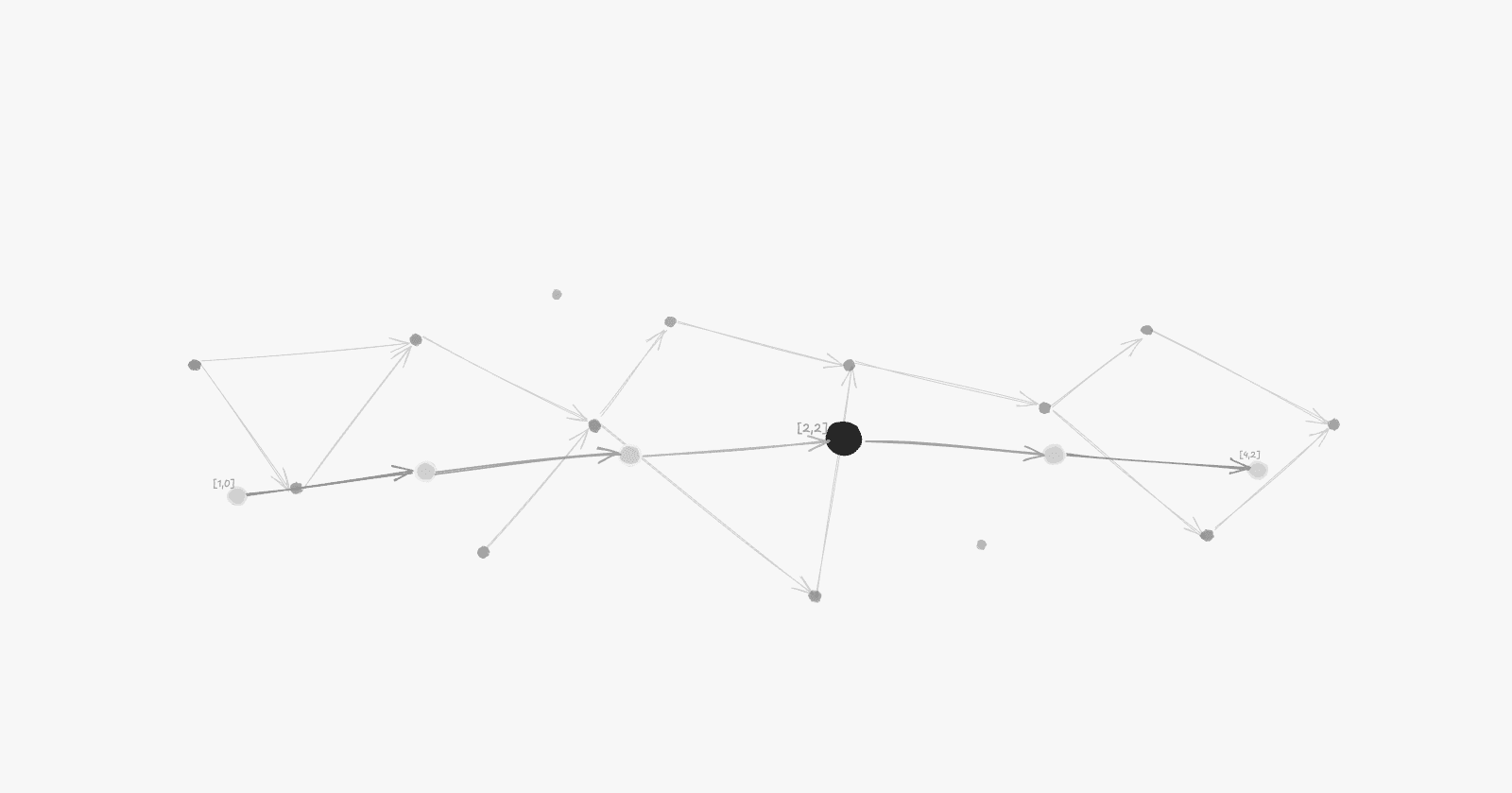
A partial order of events: arrows show causal relationships, while isolated nodes represent independent events with no defined ordering.
What “partial” really means
Partial doesn’t mean “incomplete” or “approximate.” It means: Only order what must be ordered.
If causality demands that A precede B, respect it. If causality says nothing about A and C, leave them alone.
This is not a limitation. It’s precision. It’s freedom.
Concurrency
When two events have no happens-before relationship, we call them concurrent.
Contrary to popular belief, concurrency does not mean “at the same time.” It simply means there is no causal link between them. They could have happened seconds apart. They could have happened on opposite sides of the planet. They could even have identical timestamps.
If neither could have influenced the other, they are concurrent.
That’s not ambiguity. That’s independence.
Why partial ordering is powerful
Partial ordering preserves exactly what distributed systems actually care about:
It respects causality.
It avoids inventing artificial order.
It allows independent events to proceed freely without waiting for other events.
This is why distributed systems prefer partial order whenever possible.
It maximises concurrency and minimises coordination. You don't need a "meeting" between two servers to decide who goes first if their work doesn't overlap.
But sometimes… we don't get that luxury.
Sometimes, we need a single line.
We need to decide who gets the last ticket to the concert or who spent the last dollar in a bank account.
In those moments, independence becomes a liability.
We need a way to take our causal web and flatten it into a single, reliable order.
Total ordering
Partial order is elegant. It respects causality. It avoids unnecessary constraints. It lets independent work stay independent. It stays close to reality.
But sometimes reality isn’t enough.
Sometimes we don’t just want to respect causality; we want everyone to agree on the exact same sequence of events. Even when causality doesn’t force one.
That’s total ordering.
What total order really means
A total order removes the "strangers" from the equation.
For any two events A and B, one must come before the other.
There are no unrelated events. No concurrency left undecided. No floating nodes in the graph.
Every event, no matter where it happened on the planet, gets a seat in a single, global line.
Why would we ever want that?
Because agreement is powerful.
Imagine a distributed database with three replicas. Two clients try to buy the last pair of sneakers at the same time.
Replica 1 processes Buyer A, then Buyer B.
Replica 2 processes Buyer B, then Buyer A.
Both replicas followed the rules of causality. Both are internally consistent.
And yet, they now disagree on who owns the shoes.
Same inputs. Different histories. Different state.
That’s a nightmare for a bank account, an inventory system, a file system, or a blockchain.
Nothing here is broken. Causality told us how the events were related, but it didn't give us a tie-breaker.
The system did exactly what we asked.
Which is the problem. It just wasn’t enough.
Total ordering forces every replica to say: “We will all process events in this exact order.”
That shared order becomes the system’s truth.
The cost of forcing order
Here’s the caveat: You don’t get total order for free.
If two events are concurrent, meaning causality says nothing about their order, the system has to invent one.
And inventing order requires:
communication (talking to other machines).
coordination (agreeing on a winner).
waiting (latency).
failure handling.
You pay for that agreement with latency and complexity.
This is why high-performance systems try to stay in the world of partial order for as long as possible, reaching for total order only when the business logic demands it.
Partial order is natural. Total order is negotiated.
From web to line
Partial order looks like a web. Total order flattens that web into a line.

Flattening a partial order into a total order: causal relationships are preserved, but independent events are placed arbitrarily so every machine can agree on a single sequence.
Some edges in that line are required by causality.
If A caused B, A must stay in front. But for independent events, the order is arbitrary. It’s chosen so that every machine can look at its history and see the same truth.
And that arbitrariness is fine as long as everyone chooses the same one.
Why this matters
You don’t choose one because it’s prettier. You choose based on what your system must guarantee.
Partial order maximises concurrency.
Total order maximises agreement.
If you need:
strong consistency
deterministic replay
identical replicas
You need total order. And total order doesn’t emerge naturally.
It has to be negotiated.
That negotiation is where coordination protocols live. That’s where consensus begins.
Takeaway
Clocks can’t be trusted.
And ordering was never about time.
But systems still need to agree.
So how do you build a single global sequence… without relying on time?
That’s where the real work begins.
Continue to Part 3: Constructing Order Without Time