Why time breaks distributed systems
Part 1: Why timestamps lie and ordering events isn’t as simple as it looks

When ordering events, time seems like the most obvious thing to use. If something happened at 09:00 and another at 09:01, it is clear what the order is.
Right?
Wrong.
In distributed systems, this intuition is wrong in ways that are subtle, surprising, and dangerous.
When I first started learning about distributed systems and the concept of "ordering", I had no idea how shaky the ground beneath us actually was. I assumed a timestamp was a fact.
I was wrong.
It turns out, time is less of a universal constant and more of a local, unreliable opinion.
Today, we’re going to learn the lesson that every distributed system eventually learns the hard way: Clocks lie. Sometimes they drift apart like two childhood friends losing touch. Sometimes they jump backwards without warning. And sometimes, they agree just long enough to trick you into trusting them, right before they break assumptions you didn’t even know you were making.
This series is about why clocks, as we know them, lie and why distributed systems had to invent entirely new ways to reason about order.
The lie of physical time
So what does it actually mean to say that clocks lie?
After all, your laptop has a clock. Your phone has a clock. Every machine has a clock. We have protocols like NTP (Network Time Protocol) to keep them in sync, and we even have atomic clocks in GPS satellites keeping time with absurd, terrifying precision.
Surely, "09:00:00" is "09:00:00" everywhere.
The problem isn’t that clocks are useless. The problem is that we quietly ask them to do more than they can safely promise.
We ask them to be a source of truth for the order of the universe, but they were only ever designed for human-facing timestamps, for example, to tell us when to go to lunch.
To understand where things start to break, we need to look at what “time” even means in a distributed system. In particular, we need to understand why physical time is a shaky foundation for any system that cares about the truth and about order.
That’s where we’ll start.
What we expect from physical time
When we look at a timestamp, we’re making three huge, silent assumptions:
Precision: The clock is accurate down to the millisecond.
Monotonicity: The clock only moves forward.
Universality: Other machines agree with us.
In a distributed system, all three are routinely violated.
Assumption #1: Precision implies Accuracy
We tend to think that precision and accuracy are the same thing.
They aren't.
Precision is how many digits the clock gives you.
Accuracy is whether those digits are telling the truth.
When we see a timestamp like 09:00:00.123, it feels definitive. Three decimal places. Millisecond resolution. That number looks confident. Scientific. Trustworthy.
But here’s an uncomfortable truth: precision is not the same thing as accuracy.

Precision creates the illusion of certainty. Accuracy determines how close you are to the truth.
Your system can happily print timestamps with nanosecond resolution while being wrong by tens of milliseconds - or more.
Precision is just the ability to say a number with a straight face; accuracy is the ability to actually be right.
Precision is easy. Accuracy is hard.
Most machines measure time by counting ticks from a local hardware clock (usually a tiny vibrating quartz crystal). Those ticks are frequent, so it’s easy to divide them up and label events with fine-grained timestamps.
That’s where the illusion comes from.
The clock says: 09:00:00.123 . What it really means is closer to: “As far as I can tell, it’s somewhere around 09:00, give or take.” The extra digits don’t make the clock more accurate. They just make it look more confident while lying to your face.

A precise timestamp is just a single point hiding a range of possible truths.
The hidden gap between clocks
Now imagine two machines sitting next to each other in the same data centre.
Both report millisecond-precise timestamps.
Both are “synchronised”.
Both look fine in dashboards and logs.
And yet, one might be 15ms ahead of the other.
Nothing is broken. No alarms. This is normal.
From the system’s point of view, both clocks are working as designed. From your point of view, the timestamps are already lying to you, just quietly.
Why this breaks ordering
If two events happen close together on different machines, precision gives you a false sense of certainty. You might look at this and think the order is obvious:
Machine A: 09:00:00.120
Machine B: 09:00:00.118

Two timestamps can suggest an order, even when reality makes that order unknowable.
You would assume the event on Machine B happened first. But if Machine B’s clock is lagging by just 5ms, then in reality, A actually happened first.
The problem isn’t that the clocks are "sloppy." The problem is that “accurate to the millisecond” was never a promise they could safely keep. When we rely on these numbers for ordering, we implicitly assume: “If two times differ by a few milliseconds, the order is real.”
In a distributed system, that assumption is a gamble, and the house always wins.
Precision gives us numbers. Accuracy gives us truth. Physical clocks mostly just give us the numbers.
Assumption #2: Monotonicity
In the real world, time is relentless. It is a one-way trip. You can’t unspill milk, and you can’t un-tick a second. We build our software logic on this basic law of the universe: Forward-ever, backwards-never!
But there’s a quieter, more dangerous assumption hiding behind precision: the belief that once time moves forward, it stays there.
We assume that if an event happened at 09:00:01, then nothing in the future can ever happen at 09:00:00. This feels so fundamental that we rarely question it. After all, time doesn’t go backwards.
We build systems on that assumption.
On a single machine, under ideal conditions, this mostly holds. In real systems, it absolutely does not.
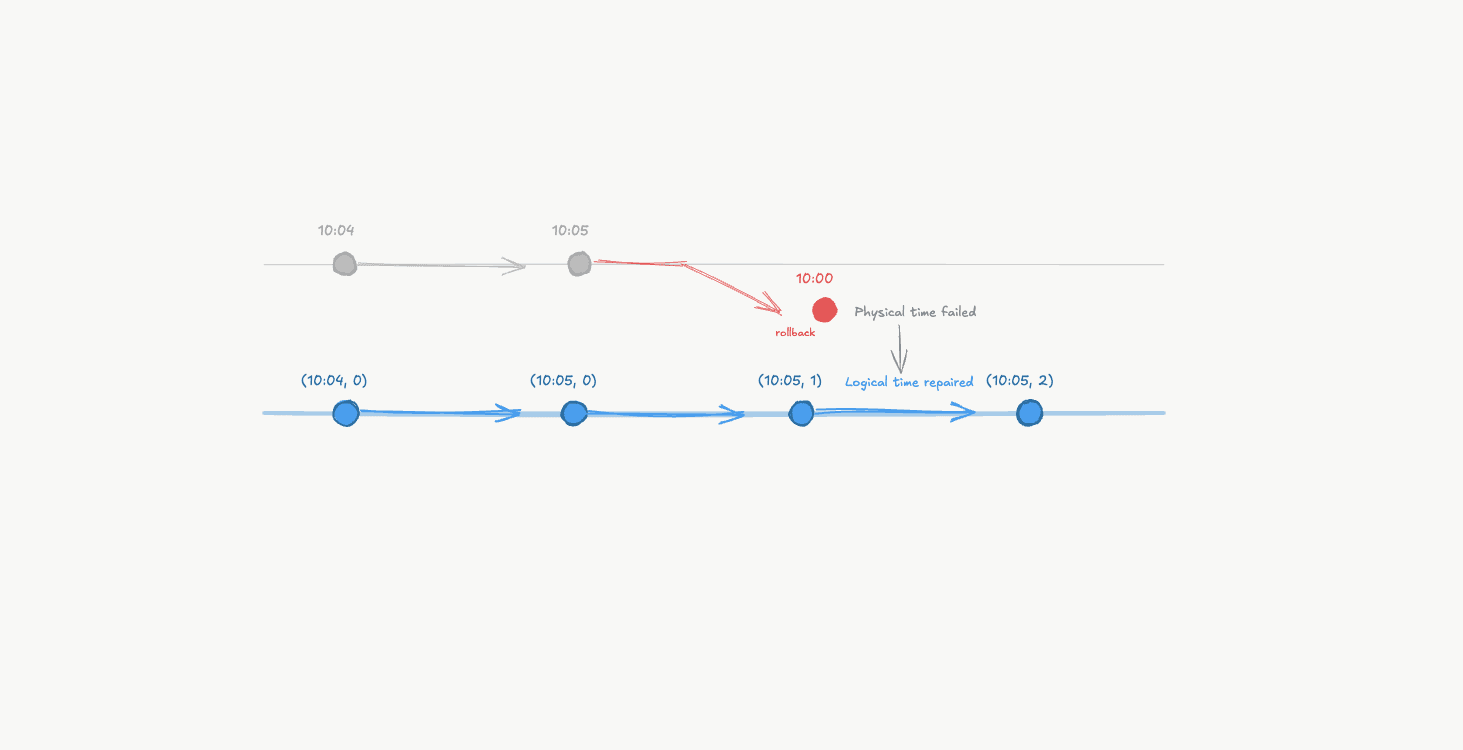
Time can go backwards
Let’s start with the most unsettling case.
Clocks can, and do, move backwards. This happens whenever the system decides its idea of "now" is wrong and tries to fix it. For example:
a clock synchronisation correction
a virtual machine pause and resume
a leap second adjustment
a manual clock change by an administrator
The system doesn’t rewind history. It simply updates its opinion of “now”.
From the clock’s point of view, that looks like this:
09:00:01.500
09:00:01.200 <- time went backwards!
Nothing crashed. Nothing is “broken”. But any code assuming monotonic time just lost its footing.

Wall-clock time can jump backwards, breaking the assumption that time always moves forward.
When time doesn’t go backwards, it “slews”
To avoid sudden jumps, many systems try to be clever. Instead of stepping the clock backwards, they slow it down until reality catches up. Time still moves forward, just not at the rate you expect.
This is called slewing.
From the outside, everything looks fine. Timestamps are increasing. But durations stretch. Timeouts fire late. Delays feel inconsistent. Imagine doing a plank for 1 minute, and it feels longer!
From the system’s point of view:
One second is no longer one second
“Now” is a moving target
Time didn’t jump. It quietly changed speed. It just changed the rules of physics while you weren't looking.

When clocks don’t jump, they drift - silently stretching time instead.
The Great Divide: Wall-Clock Time vs. Monotonic Time
At this point, most operating systems quietly admit defeat.
They expose two clocks:
Wall-clock time: Meant for humans. Can jump. Can slew. Can go backwards. It’s for knowing when to send that ”Happy New Year” text.
Monotonic time: Meant for measuring durations. Never goes backwards. Has no date. No timezone. No meaning outside the process. It’s just a counter that goes up. It doesn’t know if it is Tuesday or what year it is. It just knows it’s been ticking since the machine woke up.
Monotonic time answers: “How much time has passed?” “How long did that take?”
Wall-clock time answers: “What time do humans think it is?”
Confusing the two is one of the easiest ways to break a system.

Wall-clock time tells you what time it is. Monotonic time tells you how time has passed.
Why this breaks ordering
Ordering assumes a simple rule: Later events have later timestamps. But once time can jump or slow down, that rule collapses. An event can:
Suddenly appear to happen before the thing that caused it
Get a timestamp earlier than a previous event
Violate “read after write” assumptions
The problem isn’t bad engineering. It’s that monotonicity was never a guarantee that wall-clock time could make.
Once you notice this, it’s hard to un-see it. Precision lied quietly. Monotonicity lies loudly.
If time can’t even be trusted to move forward on one machine, the idea that multiple machines could ever agree on a global “now” should start to feel very suspicious.
Which brings us to our final, and most impossible, assumption.
Assumption #3: Universality
We’ve already faced two uncomfortable truths: clocks aren’t as accurate as they look, and even on a single machine, time doesn’t reliably move forward.
And yet, there’s usually one final assumption quietly holding our sanity together: The Backup Plan. We assume that even if my local clock is a little bit of a mess, the system as a whole is at least roughly on the same page. We believe in a shared, global “now.”
This assumption feels reasonable. We have GPS satellites, atomic clocks, and NTP (Network Time Protocol) servers. Surely, modern infrastructure can keep a handful of machines within a few milliseconds of each other. That should be good enough, right?
It isn’t.
There is no global clock
In a distributed system, "Now" isn't a fact. It is a local, subjective experience. Every machine is an island with its own clock.
Those clocks:
Tick at slightly different speeds (thanks to factors such as manufacturing differences, temperature, humidity and air pressure)
Drift apart over time
Are corrected asynchronously
Receive updates over unreliable networks
There is no central authority whispering the true time into every CPU at the same instant. What we call “clock synchronisation” is really just a best-effort agreement that is being continuously negotiated and violated the moment it’s made.

Clocks can be “in sync” and still disagree.
Synchronisation doesn’t mean agreement
Protocols like NTP don’t say: “All machines now have the same time.” They say something like “Your clock is probably within some bounds of real time.”
That bound varies and is often unknown at the moment you read the clock. It can be temporarily blown out by a spike in network traffic or a busy CPU. Two machines can both be perfectly "healthy" and "in sync" and still disagree by 20 milliseconds. In a world where a database can process thousands of transactions in a single millisecond, a 20ms gap is a canyon where assumptions go to die.
The "God's Eye View" is a Fantasy
Even if clocks were perfect (they aren’t), messages are not.
When Machine A sends a message to Machine B:
it leaves at some time
arrives later
after an unpredictable delay
By the time B sees the message, A’s idea of “now” may already be outdated.
So when B compares:
“the time in the message”
with “my current time”
It’s comparing two local opinions, separated by uncertainty and delay.
Why this breaks ordering completely
Ordering is supposed to answer a simple, vital question: Did this happen before that? Did event A happen before event B in a way that mattered?
Timestamps look like they answer this perfectly. Smaller number first, bigger number later. Case closed.
But once you accept that clocks aren’t precise, time isn’t monotonic, and machines don’t agree on “now,” you realise that timestamps have stopped answering the question you’re actually asking.
They’ve started answering a much less useful question: “Which machine had a slightly higher number on its local, unreliable crystal at the moment this happened?”
When you rely on those numbers, you're building on sand. Two events can have timestamps that suggest a clear order, while the physical reality of the system supports the exact opposite.
And the worst part? There is no way to tell which is correct.
At that point, ordering based on time isn't just fragile, it's logically meaningless. It’s like trying to measure the distance between two moving cars using a rubber band.
This isn’t a bug. This isn’t a misconfiguration. This is just physics, networks, and independent machines doing exactly what they were built to do.
Takeaway
Precision failed quietly.
Monotonicity failed loudly.
Universality never existed in the first place.
There is no shared global time in a distributed system, only local clocks, imperfectly stitched together. And once you accept that, you get to the realisation that Time is the wrong tool for reasoning about order.
Which raises the obvious question: If we can’t safely use time to order events, what on earth do we do instead?
Continue to Part 2: Ordering Without Time